
NIST SP 800-61r3: What Actually Changed and Why It Matters for Your IR Program
As I prepare to conduct an on-site Table Top Exercise (or war game if you are military minded) with my team I found myself reviewing and updating our Incident Response Plan. While ours is updated and revised frequently, it gave me pause to ask my connections around the industry regarding the status of theirs.
NIST SP 800-61 Revision 2 was officially withdrawn on April 3, 2025. If your IR plan, policy, or playbook still references it, you’re running a program anchored to a threat model from 2012. That’s not a minor version discrepancy. That’s thirteen years of incident complexity, cloud adoption, ransomware-as-a-service, and identity-based attacks that your foundational document wasn’t designed to address.
Rev 3 dropped the same day Rev 2 was pulled and most IR programs haven’t caught up yet. This post covers what actually changed, what the practical implications are, and the one structural shift that matters more than the lifecycle model everyone is focused on.
The Document Itself Changed, Not Just the Content
Before getting into the lifecycle model it’s important to touch on the style of Rev 3 itself. Rev 3 deliberately chose to be a shorter, less prescriptive document than Rev 2, and that’s a design feature. Though some may look at it as a gap or as a step backwards.
Rev 2 was 79 pages and it contained detailed operational guidance on incident handling procedures, triage methodology, network isolation techniques, forensic considerations, and communication templates. The theory was that a comprehensive guide in a single publication would be useful to practitioners across the federal space and beyond.
The problem is that the “details of how to perform incident response activities change so often and vary so much across technologies, environments, and organizations” that NIST concluded it’s “no longer feasible to capture and maintain that information in a single static publication.” That’s a direct quote from the scope section of Rev 3, and it’s a candid acknowledgment of what anyone who actually does IR work already knows: the operational specifics shift faster than a government publication cycle can track.
The replacement is a web-based companion resource hosted at the NIST Incident Response project page (csrc.nist.gov/projects/incident-response), where NIST maintains links to current implementation guidance, templates, and resources that can be updated without releasing a new version of the publication. The static PDF is now the strategic framework. The living web content is where the operational material lives.
The practical implication: if you’re only reading the Rev 3 PDF, you’re using half the resource. This is a practicality that I honestly dismissed at first because I’m jaded against how far behind the government op tempo is. However, there are actually some useful items in the operational material. For example, in the Cybersecurity and Privacy Reference Tool (CPRT) there are links to publications such as “Adversarial Machine Learning A Taxonomy and Terminology of Attacks and Mitigations” (NIST AI 100-2e2025) and “AI Risk Management Framework” (AI RFM 1.0).
The Lifecycle Model: What Replaced PICERL
The four-phase Rev 2 model that most practitioners know well mapped incident response as a cycle: Preparation, Detection and Analysis, Containment/Eradication/Recovery, and Post-Incident Activity. It was a clean mental model that held up reasonably well for the incident landscape of 2012, when incidents were relatively “rare”, scopes were narrow and well-defined, and response and recovery usually completed within a day or two.
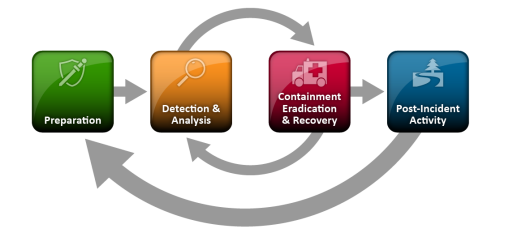
Figure 1: NIST CSF 1.0 PICERL Model
The model didn’t age well against modern incidents. A ransomware investigation running three weeks across hybrid infrastructure, with cloud, identity, endpoint, and network forensics all happening simultaneously, doesn’t fit cleanly into a linear cycle where post-incident activity feeds back into preparation.
Rev 3 replaces that model with the six CSF 2.0 functions: Govern, Identify, Protect, Detect, Respond, and Recover. The document explicitly maps where the old phases land:
| Rev 2 Phase | CSF 2.0 Functions |
|---|---|
| Preparation | Govern, Identify (all Categories), Protect |
| Detection and Analysis | Detect, Identify (Improvement Category) |
| Containment, Eradication, and Recovery | Respond, Recover, Identify (Improvement Category) |
| Post-Incident Activity | Identify (Improvement Category) |
The visual model in Rev 3 structures this as three levels. Govern, Identify, and Protect sit at the foundation as broad cybersecurity risk management activities that support IR. Detect, Respond, and Recover sit at the top as the active incident response functions. Continuous improvement, represented by the Identify function’s Improvement category (ID.IM), runs through the middle as the connective tissue that feeds lessons learned back into every function continuously rather than only after a case closes.
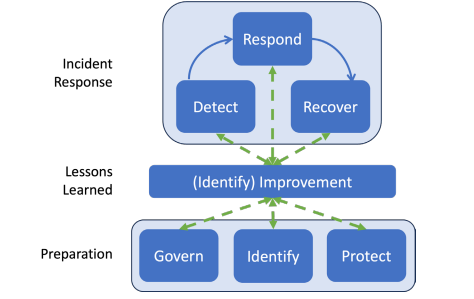
Figure 2: NIST CSF 2.0 Incident Response Life Cycle
That last piece is the real conceptual shift. Rev 2’s post-incident activity phase implied that lessons learned happened after recovery. Rev 3 explicitly frames improvement as continuous, meaning an observation made during the detection phase should feed back into Govern or Protect without waiting for the case to close. In practice, this means your IR program’s feedback loop should be running constantly, not as a quarterly retrospective exercise.
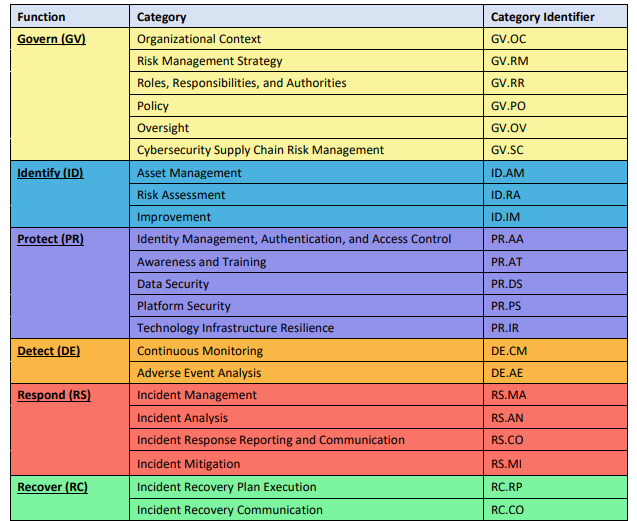
Figure 3: CSF 2.0 Core Function and Category names and identifiers
The Govern Function Is New and Matters More Than It Looks
CSF 2.0 added Govern as a sixth function that didn’t exist in CSF 1.x. It’s the function that covers organizational risk management strategy, roles and responsibilities, policies, and oversight. For IR programs, this is where the policy hierarchy lives: IR Policy, IR Plan, Playbooks, and Runbooks.
The Govern function appearing at the foundation of the Rev 3 lifecycle model is a deliberate signal that IR capability starts with organizational authority and policy clarity, not with detection tools. This is frequently the actual gap in programs that look mature on paper: there’s a SIEM, there’s an EDR, there are playbooks, but the authority structure hasn’t been defined. Who can authorize containment actions that impact production systems? Who decides whether to isolate a domain controller during an active ransomware event? Who owns the decision to notify law enforcement? Who decides if the analysts are actually allowed to enforce the Acceptable Use Policy (AUP)? That last one’s a bit of a hot button topic in our industry, but mostly a joke.
Those are Govern-layer questions. If your IR policy doesn’t answer them explicitly, you’ll be making those calls in real-time during an incident under pressure, which is exactly when you don’t want to be working through authority and escalation questions for the first time. This is also a way to help unify GRC with the technical response teams and signal that support truly is needed from the top down to succeed.
The policy hierarchy that Rev 3 supports:
IR Policy: The organizational commitment. Defines scope, authority, roles, legal obligations, and escalation thresholds. This is the document that says who can do what and when.
IR Plan: Operationalizes the policy. Defines the IR team structure, communication paths, resource requirements, and integration with business continuity. Gets reviewed annually and after major incidents.
Playbooks: Scenario-specific response procedures for defined incident types. Ransomware, BEC, credential compromise, data exfiltration. Each playbook contains decision trees, evidence capture steps, containment options, and eradication criteria.
Runbooks: Step-by-step technical procedures for specific tasks called out by playbooks. How to isolate a host in CrowdStrike Falcon. How to acquire a memory image with WinPmem. How to rotate the krbtgt account twice with the required delay.
The distinction matters operationally. A playbook tells an analyst what to do. A runbook tells them exactly how to do it. If your playbooks contain both, they become unusable under pressure because they’re too long to navigate during an active incident.
Roles and Responsibilities: The Scope Expansion
Rev 2 treated incident response as primarily the domain of incident handlers and technical staff. Rev 3 explicitly expands the role set to include leadership, legal, public affairs, human resources, physical security, and asset owners, plus a detailed treatment of third-party roles including MSSPs, cloud service providers, and retainer relationships. That being said, this is what most of the industry is already doing; but having an updated roadmap for startups to follow is just as important.
This matters for how you design your IR program’s governance structure. Legal needs to be part of IR plan review, not just incident-specific consultation. Specifically, Rev 3 calls out that legal should review IR plans, policies, and procedures to ensure compliance with applicable laws, and should review contracts with technology suppliers and third parties when there are IR implications. If your legal team hasn’t reviewed your IR plan in the last twelve months, that’s a gap.
The third-party section addresses shared responsibility explicitly. When an MSSP or CSP holds IR responsibilities, those responsibilities need to be defined in contract with clear information flows, coordination protocols, and authority to act on behalf of the organization. This is directly relevant for cloud environments, where provider and customer IR responsibilities split in ways that aren’t always obvious until an incident surfaces the ambiguity.
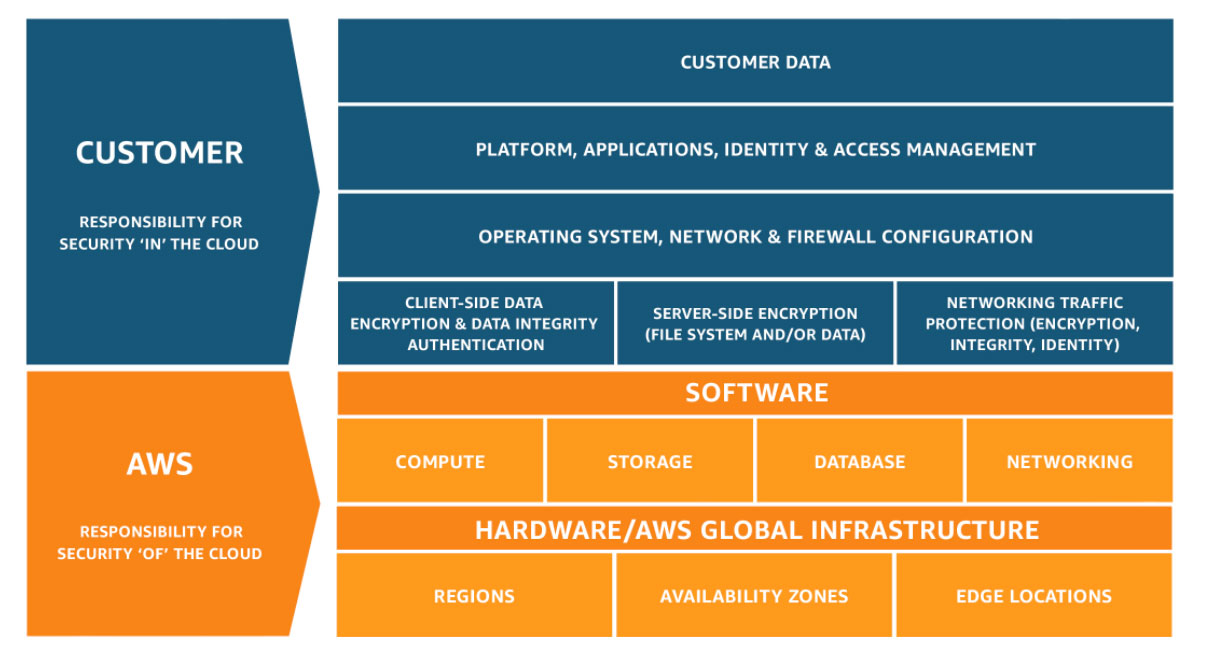
Figure 4: AWS Shared Responsibility Model
Regulatory Context Hasn’t Changed, But the Program Standard Has
The legal notification requirements that IR programs operate under didn’t change with Rev 3. However, they’re worth keeping mapped because they define your SLA constraints:
- HIPAA: 60 days from discovery for breach notification
- GDPR: 72 hours to supervisory authority
- SEC: 4 business days after determining an incident is material
- DFARS 252.204-7012: mandates that contractors safeguarding Controlled Unclassified Information (CUI) report cyber incidents within 72 hours of discovery via DC3.
- Cyber Insurance: Variable
What changed is the expectation for the program surrounding those requirements. Rev 2-aligned programs treated regulatory notification as a post-containment step. Rev 3’s CSF-aligned model, with Govern at the foundation, treats legal and regulatory obligations as design constraints on the IR program itself. Your escalation thresholds, your severity classification model, and your notification decision authority all need to be built around those timelines rather than considered after the fact. This is critical. Especially where cyber insurance is involved.
If you’re operating in FedRAMP High environments, the NIST SP 800-53 controls that map to Rev 3’s CSF 2.0 subcategories through the CPRT are the specific implementation bridge. NIST explicitly built Rev 3 as a CSF 2.0 Community Profile so that organizations using the CSF can map IR outcomes to 800-53 controls and vice versa through the Cybersecurity and Privacy Reference Tool.
If your operating in CMMC Level 2/3 environments, that implementation bridge is tricker, which for a governmental requirement makes no sense. You’d think they’d either use the related NIST 800-171 as the Community Profile baseline, or make a separate baseline for it given it’s required function. The bridge between CMMC and CSF 2.0 therefore runs: CMMC control -> 800-53 control equivalent -> CSF 2.0 subcategory.
If you want a spreadsheet-based approach rather than working through the CPRT UI, the NIST 800-171 Rev 3 publication itself contains Appendix D with the full 800-53 mapping. Pull that, filter to your Level 2/3 controls, then use the CPRT to resolve each 800-53 control to its CSF 2.0 subcategory. This is a great use-case for AI to save you some time and coffee money.
The Practical Step
Pull your current IR policy or IR plan and search it for “800-61r2” or “Revision 2.” If you find it, you have a documentation gap to close. That’s the fast version of the audit. Do the same search across your playbooks and runbooks. Reference to the old version in operational documents is a signal that the documents haven’t been reviewed since before April 2025, and it’s worth flagging to leadership because external assessors will catch it.
The more substantive exercise is a structured gap analysis against the CSF 2.0 function structure. For each function, the questions below represent the minimum bar. If any answer is “I don’t know” or “it depends who you ask,” that’s your gap.
Govern
This is where most programs are weakest and where the gap has the most operational consequence. Work through these specifically:
- Is IR authority documented? Meaning, which role has the explicit authority to authorize production system isolation, forced credential resets, or emergency firewall rules during an active incident?
- Who owns the legal notification decision? The HIPAA 60-day clock, the SEC 4-day clock, the CMMC 72-hour clock: who in your organization holds the authority to determine that a threshold has been crossed and initiate notification? That person needs to be named in your IR plan.
- Does your IR policy reference a RACI matrix or equivalent? The RACI should cover at minimum: incident declaration, severity classification, containment authorization, external notification, executive communication, and law enforcement engagement. If any of those cells is empty or contested, you have an authority gap.
- When did legal last review the IR plan? Rev 3 is explicit that legal should review IR plans, policies, and procedures for regulatory compliance and contract implications. If the answer is “never” or “more than a year ago,” schedule that review.
Identify
- Can you produce an asset inventory scoped to a specific subnet, business unit, or cloud account within an hour during an active incident? If asset inventory lives in a spreadsheet that someone manually updates quarterly, the answer is no. The quality of your asset inventory directly determines how long initial scoping takes during a ransomware event.
- Is your threat model documented and current? Not a generic “we face phishing and ransomware” statement, but a specific mapping of threat actors relevant to your sector, their documented TTPs, and the assets they’re most likely to target. MITRE ATT&CK group profiles for threat actors relevant to your environment are the starting point.
Protect
- Are control baselines defined such that deviations are detectable? This is the practical test: if an attacker disables Windows Defender on a host, does an alert fire within fifteen minutes? If a new scheduled task is created on a domain controller outside of your change window, does someone know? Protect is only useful to IR if violations of your protection posture generates signal.
Detect
- Map your detection capability against your documented threat model. ATT&CK Navigator is the right tool for this. Export your current detection rules to a Navigator layer, overlay it against the techniques used by threat actors relevant to your environment, and look at the gaps. Most programs have reasonable coverage of common initial access and execution techniques and meaningful gaps in persistence, defense evasion, and lateral movement detection. Those gaps are where dwell time accumulates.
- What is your current MTTD for a P1 incident? If you don’t know the number, you don’t have a detection baseline to improve against.
Respond
- Pull one playbook and read it cold as if you’ve never seen it. Ask: can an analyst who wasn’t on the original authoring team follow this under time pressure? Playbooks that were written by experienced practitioners often contain implicit knowledge that doesn’t survive personnel turnover. Decision trees should be explicit enough that a junior analyst can navigate them without calling the senior analyst for interpretation. In the military we call this the E3 test.
- Do your playbooks reference specific tools and specific commands, or do they describe outcomes? “Isolate the affected host” is not a runbook instruction. Rather, “In CrowdStrike Falcon, navigate to the host, select Contain Host, and document the containment timestamp in the case record” is.
- When were playbooks last tested? A playbook that hasn’t been walked through in a tabletop in the last twelve months has likely drifted from your current environment and toolset.
Recover
- Are recovery priorities documented at the business process level, not just the technical asset level? IT priorities (restore the domain controller first) don’t always match business priorities (restore the payment processing system first). That conflict surfaces during a major incident and causes delays if it hasn’t been resolved in advance.
- Have restoration procedures been tested? Backup integrity verification, restoration time estimates, and dependency sequencing all need to be validated in a non-incident context. The worst time to discover that your backup restoration process takes eighteen hours is during hour six of a ransomware response.
The output you’re looking for
Run through those questions and document every “no” or “don’t know” as a finding with an owner and a deadline. That’s your Rev 3 alignment gap analysis. Prioritize Govern findings first. They’re the ones that create decision paralysis during major incidents, and they’re the fastest to close because they’re documentation and authority problems, not technical problems.
The full publication is free at csrc.nist.gov/pubs/sp/800/61/r3/final. Read Appendix C alongside Section 2 for the fastest orientation to what specifically shifted from Rev 2. Section 3, the full Community Profile table, is reference material. Use it to cross-reference specific IR activities against CSF subcategories when building or auditing program documentation.
This was a long post, so cheers to you if you made it this far. If nothing else I hope I leave you with a useful guide on how to approach revising your own IRP. Preferably before you need to use it.